Arquitetura do Banco de Dados
Introdução
O contexto do nosso projeto envolve a manipulação de dados para treinar modelos capazes de classificar rachaduras em imagens de superfícies de edifícios e, uma vez alcançado um resultado satisfatório, aplicar essa classificação automática em produção. Além disso, desenvolvemos uma interface web acessível apenas a usuários cadastrados, onde serão exibidas todas as informações coletadas durante as expedições realizadas pela equipe do IPT.
Por isso, é fundamental contarmos com uma estrutura de armazenamento eficiente para registrar e consultar esses dados. Para atender a essa necessidade, optamos por um banco de dados relacional. Um sistema de gestão que organiza informações em tabelas compostas por linhas, que representam registros, e colunas, que definem atributos desses registros. As tabelas podem se relacionar por meio de chaves primárias e estrangeiras, o que facilita a recuperação de dados relacionados e garante a integridade referencial e a consistência das informações.
Arquitetura
A seguir, apresentamos o diagrama do nosso banco de dados e uma explicação detalhada de cada tabela e seus relacionamentos.
Figura 1 - Banco de Dados
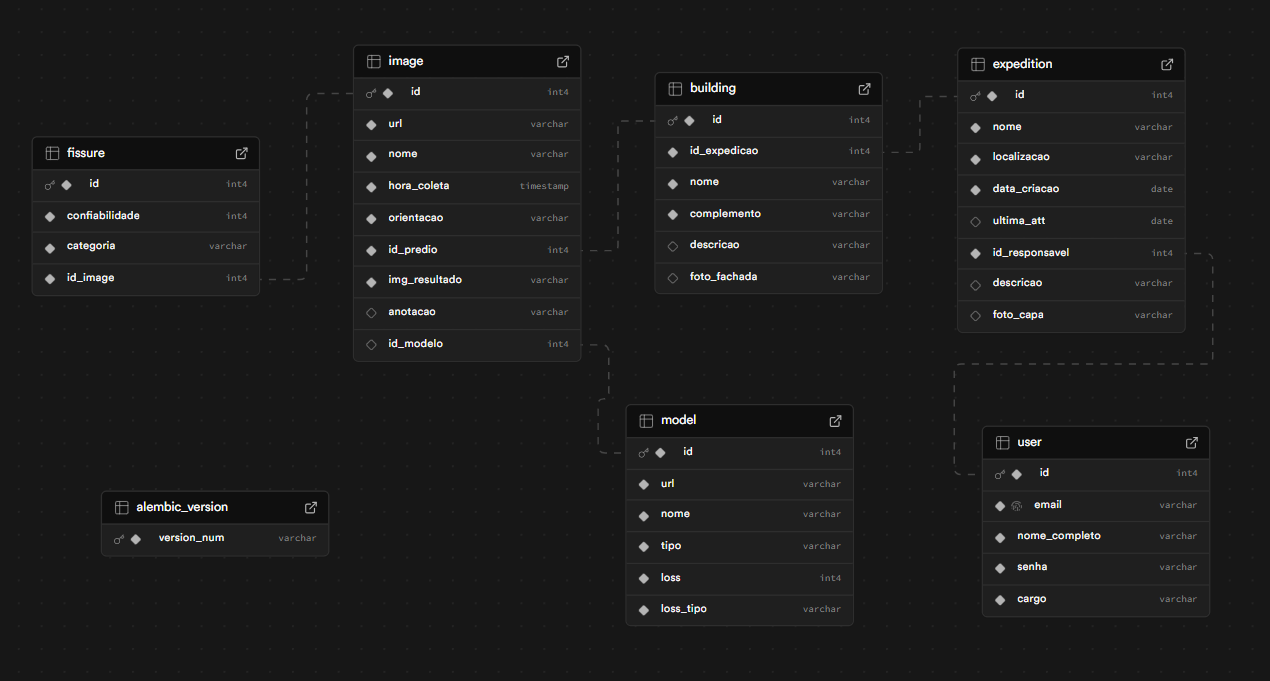
Fonte: Os autores (2025)
A estrutura do nosso banco de dados baseia-se em chaves primárias e chaves estrangeiras. A chave primária é um campo (ou conjunto de campos) que identifica de forma única cada registro em uma tabela, impedindo duplicatas; aqui, todas as nossas tabelas possuem um atributo chamado “id” como chave primária. Já a chave estrangeira é um campo que referencia a chave primária de outra tabela, criando vínculos entre os dados e garantindo a integridade referencial; no nosso projeto, elas seguem o padrão “id_(nome_da_tabela_referenciada)".
User
| Linhas | Descrição | Tipo |
|---|---|---|
| id | Identificador único de cada usuário | Chave primaria |
| Endereço de e-mail usado para autenticação | String | |
| nome_completo | Nome completo do usuário para exibição e identificação | String |
| senha | Senha de acesso (armazenada de forma segura/criptografada) | String |
| cargo | Função ou perfil de acesso do usuário dentro da aplicação | String |
Expedition
| Linhas | Descrição | Tipo |
|---|---|---|
| id | Identificador único de cada expedição | Chave primaria |
| nome | Nome atribuído à expedição | String |
| localização | Localidade onde a expedição foi realizada | String |
| data_criacao | Data em que o registro da expedição foi criado | Date |
| ultima_att | Data da última atualização feita no registro da expedição | Date |
| id_responsavel | Identificador do usuário responsável pela expedição; referência a user.id | Chave estrangeira |
| descricao | Texto descritivo detalhando o propósito e atividades da expedição | String |
| foto_capa | URL da imagem utilizado como foto de capa | String |
Building
| Linhas | Descrição | Tipo |
|---|---|---|
| id | Identificador único de cada edifício | Chave primaria |
| id_expedicao | Identificador da expedição à qual o edifício pertence; referência a expedition.id | Chave estrangeira |
| nome | Nome do edifício | String |
| complemento | Informação adicional do endereço ou referência complementar | String |
| descricao | Descrição detalhada do edifício, como características e finalidade | String |
| foto_fachada | URL da imagem da fachada do edifício | String |
Image
| Linhas | Descrição | Tipo |
|---|---|---|
| id | Identificador único de cada registro de imagem | Chave primaria |
| url | URL onde a imagem original está armazenada | String |
| nome | Nome do arquivo de imagem | String |
| hora_coleta | DateTime em que a imagem foi coletada | DateTime |
| orientacao | Orientação cardeais da fachada do edificio na qual a imagem se no momento da captura | String |
| id_predio | Identificador do prédio ao qual a imagem pertence; referência a building.id | Chave estrangeira |
| img_resultado | URL da imagem gerada pelo processamento do modelo de visão computacional | String |
| anotacao | Marcação da região da imagem que se contram as fissuras | String |
| id_modelo | Identificador do modelo utilizado na análise; referência a model.id | Chave estrangeira |
Fissure
| Linhas | Descrição | Tipo |
|---|---|---|
| id | Identificador único de cada fissura | Chave primaria |
| confiabilidade | Grau de confiança na detecção ou classificação da fissura (por exemplo, percentual de acurácia) | Integer |
| categoria | Classificação da fissura conforme seu tipo | String |
| id_image | Identificador da imagem à qual a fissura pertence; referência a image.id | Chave estrangeira |
Model
| Linhas | Descrição | Tipo |
|---|---|---|
| id | Identificador único de cada modelo | Chave primária |
| url | Referência à localização do arquivo do modelo em storage | String |
| nome | Nome de identificação do modelo | String |
| tipo | Categoria do modelo | String |
| loss | Valor da função de perda (loss) obtido ao final do treinamento | Integer |
| loss_tipo | Nome da função de perda utilizada no treinamento (por exemplo, “cross_entropy”, “MSE”) | String |
Versionamento
Como usamos Flask e SQLAlchemy, optamos por Alembic para controlar o versionamento do esquema de banco de dados de forma integrada.
O versionamento de banco de dados é o controle sistemático das alterações no esquema (tabelas, colunas, constraints) ao longo do tempo. Isso garante rastreabilidade, reversibilidade e consistência entre ambientes (desenvolvimento, teste, produção).
Usando Alembic
OBS: A configuração e manipulação do Alembic deve ser feito dentro da pasta back-end
- Instalar
pip install alembic
- Inicializar (uma vez)
alembic init alembic
Cria alembic.ini, pasta alembic/versions/ e env.py.
-
Configurar
- Em
alembic.ini, ajustesqlalchemy.urlcom sua string de conexão.
Exemplo:
sqlalchemy.url = postgresql+psycopg2://meu_usuario:minha_senha@meu_host:5432/meu_banco- Em
alembic/env.py, importedb.metadata(do Flask-SQLAlchemy) e atribua atarget_metadata.
Exemplo:
from config.database import db - Em
-
Gerar uma migration
Após alterar seus models, rode:
alembic revision --autogenerate -m "descrição da mudança"
- Aplicar migrations
Para atualizar o banco até a última versão:
alembic upgrade head
- Reverter
Para voltar uma versão:
alembic downgrade -1
Conclusão
Em resumo, nossa base relacional sustenta todo o fluxo do projeto: desde o armazenamento organizado das imagens e metadados usados no treinamento e classificação automática de fissuras até o registro detalhado das expedições do IPT na interface web. Com chaves primárias garantindo unicidade e chaves estrangeiras mantendo os vínculos entre entidades, temos um sistema consistente, confiável e preparado para evoluir conforme novas necessidades do projeto.